Q & A 问答社区
QA 是一个基于 B/S 架构而设计开发的问答网站。

![]()
![]()
主要为用户提供以下服务:
- 问题发布
- 评论
- 用户私信
- 关注
- 站内全文检索
技术选型
Spring Boot + MyBatis + MySQL + Redis + FreeMarker
注意,为保证系统正常运行,请安装并创建好以下环境:
- MySQL
- Redis
- Solr(搜索服务时用到)
功能描述
注册登录
为了保证用户信息安全,系统对用户密码采用「salt + md5」方式进行加密/脱敏。用户注册/登录成功后,系统会生成一个 ticket ,将 ticket 与用户 id 相关联,并将此信息插入到数据库表 login_ticket 中,同时将 ticket 添加至 cookie 响应给客户端。
用户每次请求页面的时候,都需要先经过 PassportInterceptor 拦截器,拦截器判断此 ticket 是否真实有效,若是,根据 ticket 对应的用户 id ,查出相应用户信息,并添加至页面上下文中。
用户内容发布
- 问题发布
- 评论发布
- 私信发布
在以上 UGC (User Generated Content, 用户产生的内容)中,系统都会进行 HTML 标签及敏感词过滤,这在一定程度上防止网站被注入脚本或者充斥着不良信息。
若没有对 HTML 标签进行处理,当用户发布的内容含有如
<script>alert("hahah");</script>时,网站页面每次加载此内容时都会弹出消息框。
对于敏感词过滤,按照常规的思维,也是最简单的方式,就是:对于每个敏感词,都在文本中查找该敏感词是否出现,出现则进行替换。这种方式,每个敏感词都要在一段文本中进行遍历查找,复杂度非常高。
本项目采用「前缀树」方式实现敏感词过滤,空间换时间,效率较高。前缀树结点结构如下:
class TrieNode {
// 标记是否为敏感词结尾
boolean end;
// 该结点的所有直接子结点
Map<Character, TrieNode> subNodes = new HashMap<>();
// 添加一个子结点
void addSubNode(Character key, TrieNode node) {
subNodes.put(key, node);
}
// 根据key获取子结点
TrieNode getSubNode(Character key) {
return subNodes.get(key);
}
}
后台从敏感词文件 SensitiveWords.txt 顺序读取每一行建立前缀树。进行过滤时,遍历需要过滤的文本,用星号替换发现的敏感词。假设文本长度为 len,前缀树的最大高度为 h,那么此算法的最坏时间复杂度为 O(len*h)。
算法比较
假如敏感词平均长度为10,数量为100000,文本长度为 len。
常规方式,复杂度O(100000 * (len + 10));前缀树算法复杂度O(10 * len)。
对于评论功能,系统建立的是一个统一的评论服务中心,通过 EntityType 与 EntityId 识别所评论的实体。用户对于问题/评论的回复,都可以应用此服务。查询某实体下的评论时,同样根据 EntityType 和 EntityId 查询即可。
用户内容赞踩
赞踩功能采用「Redis」作为数据存储。Why Redis?
比较一下 Redis 和 MySQL:
- Redis: key-value数据库,数据放在内存
- MySQL: 关系型数据库,数据放在磁盘
Redis 适合放一些频繁使用、比较热的数据。因为数据放在了内存中,读写性能卓越。
| Redis 类型 | 数据结构 | 应用场景 |
|---|---|---|
| List | 双向列表 | 最新列表、关注列表 |
| Set | 无序集合 | 赞踩、抽奖、已读、共同好友 |
| SortedSet | 优先队列 | 排行榜 |
| Hash | 哈希表 | 不定长属性数 |
| KV | 单一数值 | 验证码、PV、缓存 |
除了用户内容赞踩,在本项目中,Redis 还应用于以下场景:
- 异步事件处理
- 关注服务
- Timeline
本小节讨论用户内容赞踩服务。
用户对某一实体点赞,会将”LIKE:ENTITY_TYPE:ENTITY_ID”作为 key ,用户 id 作为 value ,存入 like 集合中。同时移除 unlike 集合中该 key 对应的用户 id。点踩服务反之。 最后将点赞数响应给页面。
异步事件处理
本项目涉及到多种异步事件的处理。如:
- 用户评论了某个问题
- 用户点赞了某条评论
- 用户关注了另一个实体
这些动作并不是单一的,它们会触发一些后续的操作:
用户评论了某个问题,系统除了处理“评论”这个动作外,还需要给该问题对应的用户发送一条消息,通知说“xx评论你的问题”,或者还需要给用户增加积分/经验…
事件触发者并不关心这些后续的任务,系统处理完某个动作后就可以将结果返回给触发者,而后续的任务交给系统进行异步处理即可。
因此,设计一个异步事件处理框架尤为重要。 本项目的异步框架如下图所示:
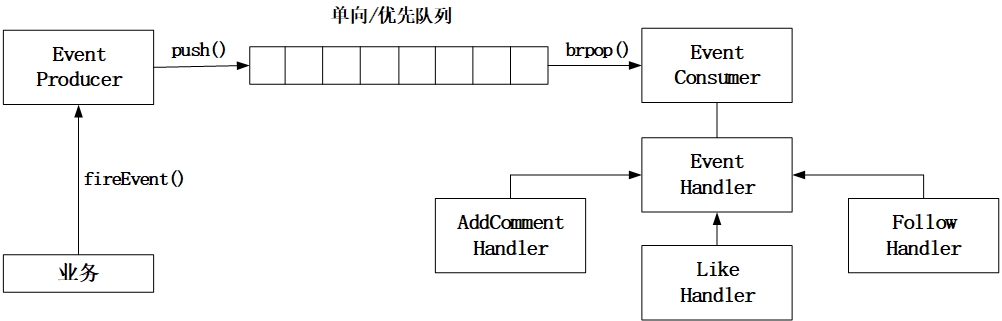
业务触发一个异步事件,EventProducer 将该事件(EventModel)序列化并存入队列(Redis List)中,EventConsumer 开启线程循环从队列中取出事件,识别该事件的类型,找出该类型对应的一系列 EventHandler,交由这些 Handler 去处理。
EventModel 的设计如下:
class EventModel {
// 事件类型
EventType type;
// 事件触发者
int actorId;
// 事件对应的实体
int entityType;
int entityId;
// 事件对应的实体的Owner
int entityOwnerId;
// 一些扩展字段
Map<String, String> exts;
}
SNS 关注服务
与评论功能类似,对于关注功能,系统同样建立了一个统一的关注服务中心,用户可以关注不同的实体(问题/用户),只需要通过 EntityType 和 EntityId 识别即可。 在数据存储方面,采用 Redis 的 zset 完成,原因有以下几个:
- zset 有序,系统可以根据用户关注实体的时间倒序排列,获取最新的关注列表;
- zset 去重,用户不能重复关注同一个实体;
- zset 可以获取两用户之间的共同关注。
一个用户,系统存储两个集合:
①保存用户关注的实体;②保存关注用户的人。
即 A 是 B 的粉丝,B 是 A 的关注对象。[ 参考资料 ]
用户关注了一个问题,需要发生两个动作:
- 将问题存入①中
- 在②中存入用户 id
这两个动作必须同时发生,因此,这里用到了 Redis 事务保证原子性和数据的一致性。
另外,对于关注功能,如前面所说,会触发异步事件,将消息通知被关注的实体 / 实体 Owner。
用户内容排名
本系统未采用排名算法。若要了解相关算法,可以参考如下资料:
- 基于用户投票的排名算法(一):Delicious和Hacker News
- 基于用户投票的排名算法(二):Reddit
- 基于用户投票的排名算法(三):Stack Overflow
- 基于用户投票的排名算法(四):牛顿冷却定律
- 基于用户投票的排名算法(五):威尔逊区间
- 基于用户投票的排名算法(六):贝叶斯平均
Timeline Feed 流服务
当用户更新动态时,该用户所有粉丝都可以在一定时间内收到新的动态(也称为新鲜事、feed),可以由 “推拉模式” 实现。
| 模式 | 定义 | 优缺点 |
|---|---|---|
| 推 | 事件触发后广播给所有粉丝。 | 对于粉丝数过多的事件,后台压力较大,浪费存储空间; 流程清晰,开发难度低,关注新用户需要同步更新 feed 流。 |
| 拉 | 登录打开页面时,根据关注的实体动态生成 Timeline 内容。 | 读取压力大,存储占用小,缓存最新读取的 feed,根据时间分区拉取。 |
| 推拉 | 活跃/在线用户推,其他用户拉。 | 降低存储空间,又满足大部分用户的读取需求。 |
具体来说,推模式就是:事件触发后产生 feed,触发事件的用户下所有粉丝的 Timeline(redis list 实现)中都存入该 feed 的 id。而拉模式,就是当前用户去拉取自己关注的人的 feed。
这里其实是观察者模式的一个具体应用。推模式就是主题对象直接将数据传送给观察者对象;拉模式则是观察者对象间接去获取变化后的主题数据,观察者自己把数据“拉”过来。
更多关于推拉模式,可以参考[ 微博 feed 系统推拉模式 ]。
网站爬虫
由于系统初始数据较少,为了丰富网站内容,本项目初期采用 pyspider 实现对 V2EX 网站的数据爬取,存储到后台数据库,并展示在前端页面上。
安装 pyspider:
pip install pyspider
启动 pyspider:
pyspider
近期,项目更新了爬虫服务。新的爬虫服务采用Jsoup第三方库,通过Jsoup发送url请求,并获得Document文档对象,通过CSS选择器方式找到相应的节点,解析数据,并存储到数据库中。新的服务不仅对V2EX上的question进行爬取,还把question相关的comment一起爬取下来,网站内容更加丰富。
本爬虫服务采用 Spring @Async 异步进行爬取,避免因页面阻塞而影响用户体验的情况。当然,也可以使用线程池的方式。不过使用 Spring 的话,只需要@EnableAsync和@Async两个注解,更加方便。
爬取过程中要注意设置request请求头,模拟浏览器行为,同时爬取速度不能过快,否则 IP 容易被封。
爬虫会给别人家网站服务器带来负担,be a responsible crawler。
站内全文检索服务
数据大致分为两种:
- 结构化数据: 指具有固定格式或有限长度的数据,如数据库,元数据等。
- 非结构化数据: 指不定长或无固定格式的数据,如邮件,word文档等。
全文检索大体分两个过程,索引创建 (Indexing) 和搜索索引 (Search) 。
- 索引创建:将现实世界中所有的结构化和非结构化数据提取信息,创建索引的过程。
- 搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
本项目在全文检索服务上采用 Solr 框架,中文分词采用 Solr 自带的中文分词插件 solr_cnAnalyzer 。
这个项目还有很多需要优化,我会抽空更新。